Take advantage of an operational data store to consolidate data from across your organization and transform it for use in real time.


Data is the lifeblood of the modern organization. It is constantly moving and changing, vast in scale and dizzying in velocity. It is widely distributed, available everywhere, driving operations and guiding strategic decisions.
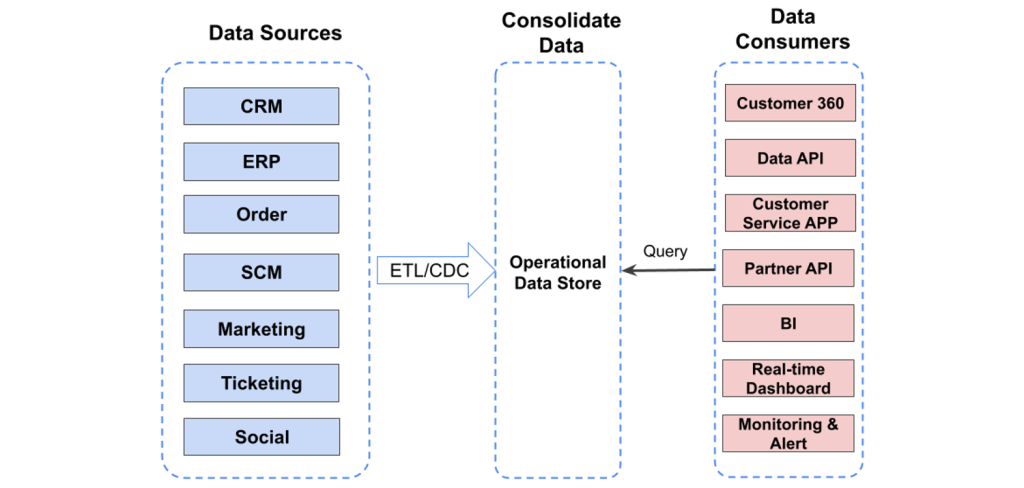
This explains why more and more organizations are implementing an “operational data store.” An operational data store acts as an intermediary between a vast array of data sources and data consumers, including business analysts, developers, and senior decision-makers.
An operational data store is quite different from a data warehouse, which is a repository where data is shaped and organized for business intelligence and real-time data serving.

IDG
An operational data store is more like a temporary landing zone where data from across the organization is consolidated and transformed for use in real time. Data warehouses are for deep analysis and historical reflection. The operational data store, on the other hand, is for understanding the state of your business right now.
The operational data store synthesizes data from sources across the organization: CRM, IT ticketing, HR, marketing, customer service, and other functions.
Common use cases for an operational data store include:
- Supporting data-driven decision-making in real time
- Improving data governance, privacy, and compliance
- Modernizing legacy systems through data-as-a-service (DaaS)
- Efficient data processing.
The operational data store requires a robust technological infrastructure. Here we will discuss implementing an operational data store in TiDB, an open-source distributed SQL solution designed for high-performance applications.
Technological requirements
When selecting a data solution for your operational data store, there are four main requirements to keep in mind.
- Scalability. The operational data store must be able to collate huge volumes of data, including user identity and activity, from multiple systems, and support real-time queries.
- Performance. Unlike a data warehouse, where queries can run overnight, operational data store users expect real-time responses. Also, for the purposes of SLAs, system latency needs to be kept to a minimum.
- Reliability. Due to its always-on nature, an operational data store needs the ability to maintain operations under intense loads while isolating system failures.
- Flexible queries. The operational data store needs to support a range of use cases from business intelligence to real-time data processing and data serving. Providing enough capability and flexibility to query large volumes of data is critical.
Key considerations
Once you have selected your data solution—TiDB in this case—there are four areas to consider when implementing an operational data store.
Capacity planning
First determine the size of the clusters you need to support the workload. Since TiDB separates storage from query processing (see below about processing at the storage node), you will need to size your SQL and storage layers independently. Consider these factors when making your estimations.
- Storage needs will be determined by your overall data volume but also by query workload, because some queries will be pushed down to the storage layer for processing. That means you will need to consider not just raw storage, but compute for TiDB’s storage-based query workloads. For the SQL layer, start with a rough estimate to get the whole picture, then test with a real-world workload. A typical starting point for each node is 2TB to 4TB of storage and 16 cores per node, though especially heavy workloads might demand additional compute.
- Throughput mostly affects the SQL nodes. The key metric here is queries per second (QPS). It is difficult to formulate a general rule, since workloads differ so widely. Running your own benchmarks can give you a sense for how many QPS each node can handle, and can provide a starting point for further exploration. Perform your tests with real-world data and workloads to get a more accurate estimate. TiDB compute is relatively easy to add and remove, so despite the trial and error nature of this phase, implementation typically does not take long.
Schema design
If you are migrating from a single-node relational databases, such as PostgreSQL or Microsoft SQL Server, you can change the syntax of your queries while keeping your schema intact. You will probably need to re-consider the indexes—and possibly add more—or change the owners of certain columns.
If you are performing a greenfield implementation, you can take advantage of TiDB’s support for online schema changes. This approach has the advantage of allowing you to design for the needs you have today, rather than trying to envision your needs in the future. As your data volume grows or you need to generate new reports and queries, or change an index, you can simply implement the change through the online DDL.
This points up a major difference between NoSQL solutions and TiDB. While NoSQL solutions are easy to implement on scalable storage, users often find themselves limited by their inability to do more than simple key-value gets/scans as their needs become more complex. With TiDB’s online schema change, you can quickly build the first version of your operational data store without worrying much about future needs, knowing you can always adjust the schema as your needs grow.
Ecosystem
Adopting TiDB as an operational data store enhances an organization’s ability to leverage real-time data across diverse operations, fostering enhanced decision-making and operational efficiency. Here we’ll explore how to integrate TiDB with your existing data ecosystem.


IDG
Compatibility and data ingestion from various upstreams
Successful operational data store implementation begins with effective data ingestion from various upstream systems. For this, TiDB provides several relevant features:
- Compatibility and connectors: TiDB supports a wide range of data ingestion protocols and offers connectors for popular databases such as MySQL, as well as for Apache Kafka for message streaming. This ensures that TiDB can integrate smoothly with existing data infrastructures, making it a central point for operational data activities.
- Standard SQL interface: By providing a fully compatible MySQL interface, TiDB allows existing applications and tools to communicate with it without requiring changes in the application code. This SQL compatibility reduces the friction involved in replacing or integrating new components within the data stack.
Synchronizing with data warehouses and data lakes
Once data is ingested, the next step is to synchronize that data with data warehouses and data lakes for comprehensive analysis and storage. TiDB also provides robust tools and features for this purpose:
- TiCDC: TiDB’s Change Data Capture (CDC) feature streams changes made to the database in real time. This is essential for maintaining data consistency between TiDB and external data stores like data lakes and warehouses, enabling real-time analytics and extract, transform, and load (ETL) processes.
- TiDB Lightning: For efficient large-volume data transfers from data warehouses or data lakes into TiDB, TiDB Lightning is the tool of choice. It facilitates fast and reliable batch data loading, making it ideal for initializing new database clusters with historical data or merging batch analytics results into the operational data store.
Integration with applications and BI tools
A versatile operational data store must seamlessly integrate with both the consuming applications and the analytical tools that help businesses derive actionable insights:
- API accessibility: For custom applications, TiDB supports numerous APIs that enable direct interaction with the data layer, facilitating custom operational dashboards and real-time data functionalities within proprietary systems.
- Broad BI tool compatibility: Thanks to TiDB’s SQL interface, it integrates effortlessly with a wide range of BI tools, such as Tableau, Microsoft Power BI, and Looker, allowing for complex data analyses and visualizations directly on real-time data.
- Integration with popular compute engines: TiDB works seamlessly with Apache Spark and Apache Flink, enabling complex data processing and analytics workflows. This integration allows businesses to perform large-scale data processing and stream analytics, enhancing real-time data processing capabilities. For instance, data analysts can use Spark for complex batch processing and machine learning models, while Flink can be employed for real-time stream processing and event-driven applications.
Multi-tenant environments
Unlike the storage at the back of an operational app, an operational data store is usually shared among several services. Those services may come with different requirements and priorities. Properly allocating and isolating resources among these services not only can improve the user experience but also can be more cost-effective.
TiDB provides an advanced feature called Resource Control, which is a fine-grained resource usage control mechanism. This resource control mechanism allows for precise management of compute and storage resources, ensuring that each service receives the necessary resources to perform optimally without interfering with others. This capability not only enhances the overall user experience by maintaining high performance and availability but also optimizes operational costs. Services can scale resource usage up or down based on real-time demands, making the operational data store both flexible and cost-effective.
By implementing TiDB’s resource control features, organizations can ensure a balanced and efficient distribution of resources, which is critical for maintaining the stability and responsiveness of shared data environments.
Making the most of data
In an era of fast-paced innovation and global competition, data plays an instrumental role in driving business decisions and operational efficiency. An operational data store like the one described in this article can help businesses achieve seamless connectivity between varied data sources, data warehouses, data lakes, and end-user applications while harnessing real-time insights for strategic decision-making. TiDB’s robust data ingestion, data synchronization, and extensive compatibility with BI tools, along with its ability to handle large-scale data operations with minimal latency, make it a formidable choice for this purpose.
Whichever solution you use to build your operational data store, the result is more than just another technology solution. It’s a way to embrace the new business reality, where data is the key to making operations robust, adaptable and aligned with your strategic goals.
Li Shen is senior vice president at PingCAP, the company behind TiDB.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.









